A Video Explaining LNA Noise Temperature Calculations
Over on YouTube Adam 9A4QV (creator of the LNA4ALL and other products) has uploaded a video that explains Friis formula for noise, using simple calculations and theory. These calculations explain why an LNA can significantly help reception on L-Band with an RTL-SDR. In his video he uses graphs and tables provided in this document released by the US Naval Academy. At the end of this post we attached images of the graph and table that he uses in the videos calculations for easy access.
The calculations show how the noise figure and gain of the first LNA in the system dominates the result. The final result of his video shows that using an LNA with a noise figure of 1 dB and 16 dB gain can give an improvement in SNR of about 7.8 dB over a standard RTL-SDR which has a noise figure of 6 dB. This is the improvement on L-band from simply placing the LNA by the dongle, and it does not take into account the extra improvement that could be had by placing it by the antenna, if a run of coax is used. The equations can also be adapted to other frequencies, and they show that as the frequency decreases, the effect of the noise figure of the LNA becomes less important.


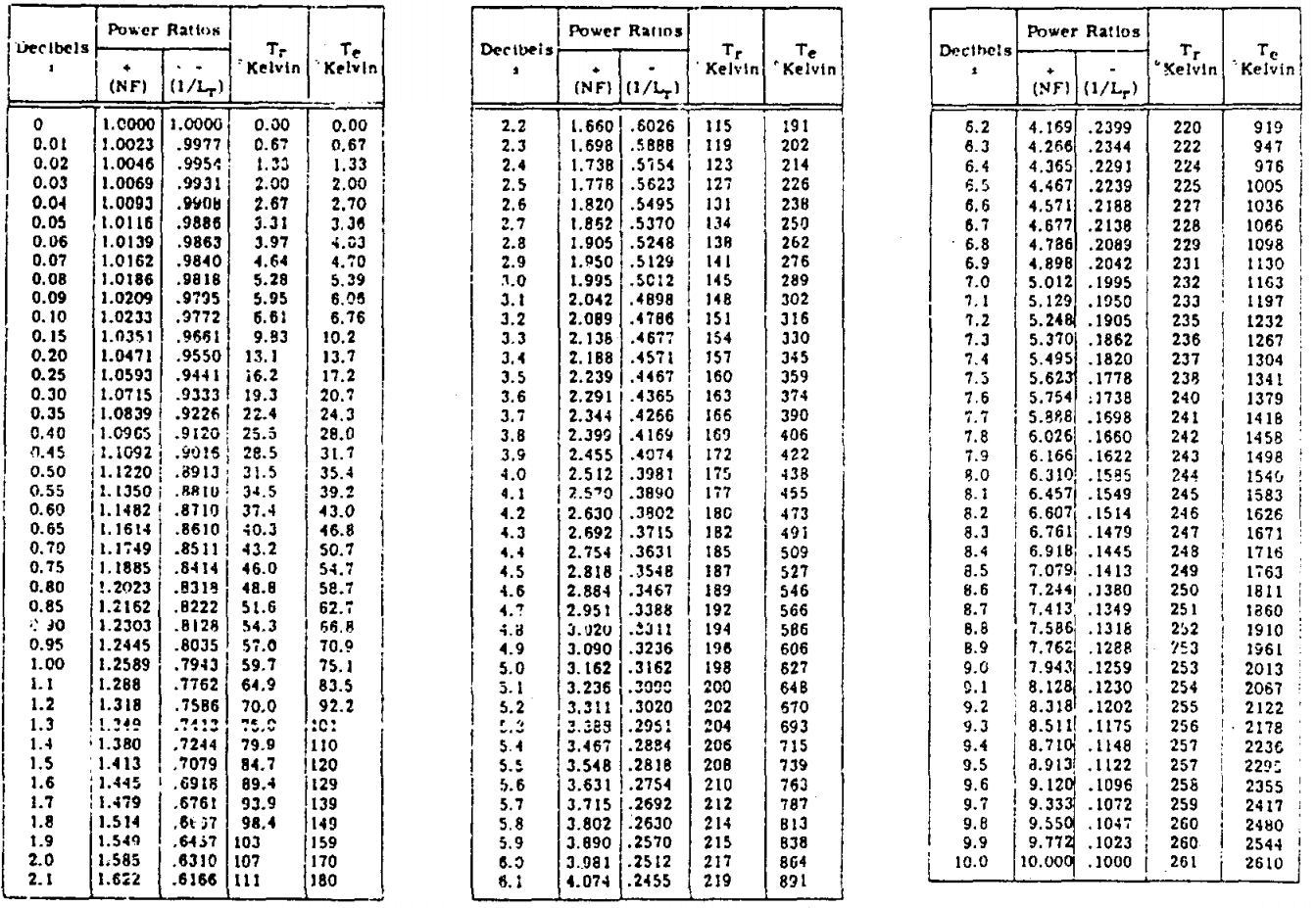




























The calculation is correct for 1.7.GHz.
At 500 MHz the improvement in S/N will be 3dB.
At frequencies below 50 MHz there will be no improvement.